Supervised Learning
What is Supervised Learning?
Supervised Learning is the process of making an algorithm to learn to map an input to a particular output. This is achieved using the labelled datasets that you have collected. If the mapping is correct, the algorithm has successfully learned.
Else, you make the necessary changes to the algorithm so that it can learn correctly. Supervised Learning algorithms can help make predictions for new unseen data that we obtain later in the future.
This is similar to a teacher-student scenario. There is a teacher who guides the student to learn from books and other materials.The student is then tested and if correct, the student passes. Else, the teacher tunes the student and makes the student learn from the mistakes that he or she had made in the past. That is the basic principle of Supervised Learning.

How Supervised Learning Works?
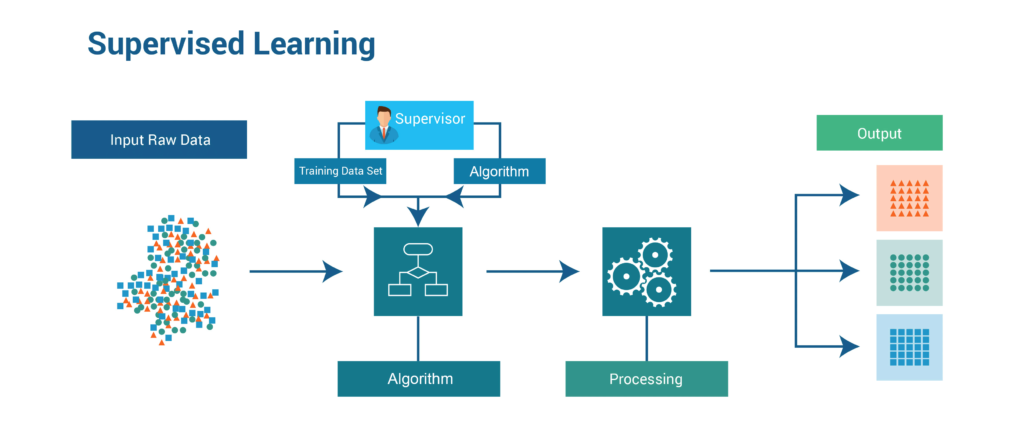
In supervised learning, models are trained using labelled dataset, where the model learns about each type of data. Once the training process is completed, the model is tested on the basis of test data (a subset of the training set), and then it predicts the output.The working of Supervised learning can be easily understood by the below example and diagram:
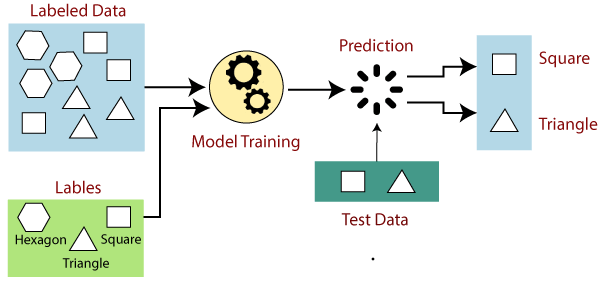
Suppose we have a dataset of different types of shapes which includes square, rectangle, triangle, and Polygon. Now the first step is that we need to train the model for each shape.
- If the given shape has four sides, and all the sides are equal, then it will be labelled as a Square.
- If the given shape has three sides, then it will be labelled as a triangle.
- If the given shape has six equal sides then it will be labelled as hexagon.
Now, after training, we test our model using the test set, and the task of the model is to identify the shape.
The machine is already trained on all types of shapes, and when it finds a new shape, it classifies the shape on the bases of a number of sides, and predicts the output.
Best practices for Supervised Learning:
- Before doing anything else, you need to decide what kind of data is to be used as a training set.
- You need to decide the structure of the learned function and learning algorithm.
- Gather corresponding outputs either from human experts or from measurements
Why is it Important?
- Learning gives the algorithm experience which can be used to output the predictions for new unseen data
- Experience also helps in optimizing the performance of the algorithm
- Real-world computations can also be taken care of by the Supervised Learning algorithms
Advantages of Supervised Learning:
- Supervised learning allows you to collect data or produce a data output from the previous experience
- Helps you to optimize performance criteria using experience
- Supervised machine learning helps you to solve various types of real-world computation problems.
Disadvantages of Supervised Learning:
- You need to select lots of good examples from each class while you are training the classifier.
- Classifying big data can be a real challenge.
- Training for supervised learning needs a lot of computation time.
Challenges in Supervised machine learning:
- Irrelevant input feature present training data could give inaccurate results
- Data preparation and pre-processing is always a challenge.
- Accuracy suffers when impossible, unlikely, and incomplete values have been inputted as training data
- If the concerned expert is not available, then the other approach is "brute-force." It means you need to think that the right features (input variables) to train the machine on. It could be inaccurate.
Types
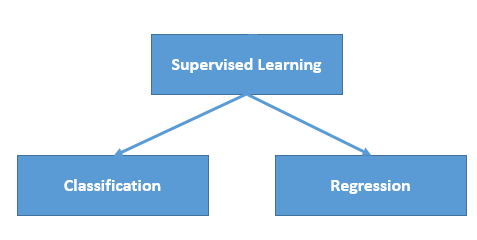
Regression:
Regression technique predicts a single output value using training data. Example: You can use regression to predict the house price from training data. The input variables will be locality, size of a house, etc.
Strengths: Outputs always have a probabilistic interpretation, and the algorithm can be regularized to avoid overfitting.
Weaknesses: Logistic regression may underperform when there are multiple or non-linear decision boundaries. This method is not flexible, so it does not capture more complex relationships.
Here are a few types of Regression Algorithms:
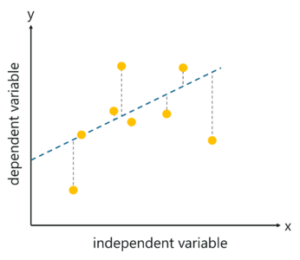
1. Linear Regression
This algorithm assumes that there is a linear relationship between the 2 variables, Input (X) and Output (Y), of the data it has learnt from. The Input variable is called the Independent Variable and the Output variable is called the Dependent Variable. When unseen data is passed to the algorithm, it uses the function, calculates and maps the input to a continuous value for the output.
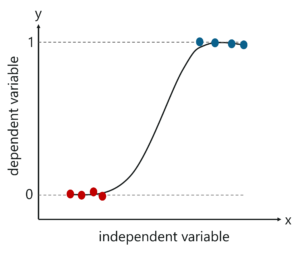
2. Logistic Regression
Logistic regression method used to estimate discrete values based on given a set of independent variables. It helps you to predicts the probability of occurrence of an event by fitting data to a logit function. Therefore, it is also known as logistic regression. As it predicts the probability, its output value lies between 0 and 1.
Classification:
Classification means to group the output inside a class. If the algorithm tries to label input into two distinct classes, it is called binary classification. Selecting between more than two classes is referred to as multiclass classification. Example: Determining whether or not someone will be a defaulter of the loan.
Strengths: Classification tree perform very well in practice
Weaknesses: Unconstrained, individual trees are prone to overfitting.
Here are a few types of Classification Algorithms:
1. Naïve Bayes Classifiers:
Naïve Bayesian model (NBN) is easy to build and very useful for large datasets. This method is composed of direct acyclic graphs with one parent and several children. It assumes independence among child nodes separated from their parent.
2. Decision Trees:
Decisions trees classify instance by sorting them based on the feature value. In this method, each mode is the feature of an instance. It should be classified, and every branch represents a value which the node can assume. It is a widely used technique for classification. In this method, classification is a tree which is known as a decision tree.
It helps you to estimate real values (cost of purchasing a car, number of calls, total monthly sales, etc.).
Applications of Supervised Learning:
- BioInformatics
- Speech Recognition
- Spam Detection
- Object-Recognition for Vision
